Hot Chips 2020 Live Blog: Cerebras WSE Programming (3:00pm PT)
by Dr. Ian Cutress on August 18, 2020 6:00 PM EST- Posted in
- AI
- Live Blog
- Cerebras
- Wafer Scale
- CS-1
- Hot Chips 32
- WSE


06:03PM EDT - Cerebras did the wafer scale - a single chip the size of a wafer
06:03PM EDT - Here's WSE1


06:04PM EDT - Uses standard tools like TensorFlow and pyTorch with Cerebras compiler
06:04PM EDT - CS-1 fits in standard 15U rack

06:04PM EDT - 400k cores
06:04PM EDT - (Costs a few $mil each)
06:05PM EDT - No DRAM, full on-chip SRAM
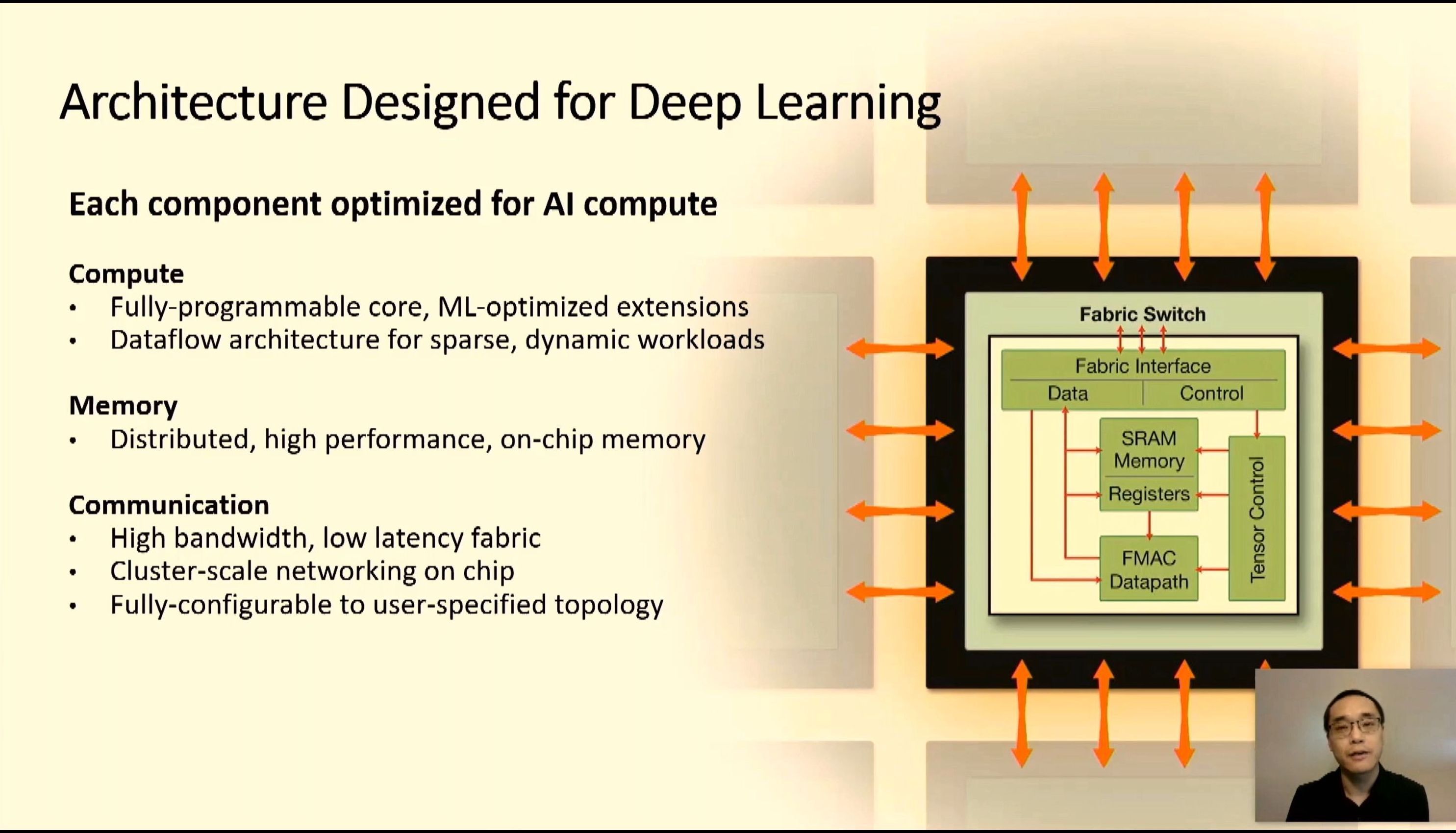
06:05PM EDT - 3D mesh network
06:06PM EDT - Allows all 400k cores to work on the same problem
06:06PM EDT - Linear perf scaling

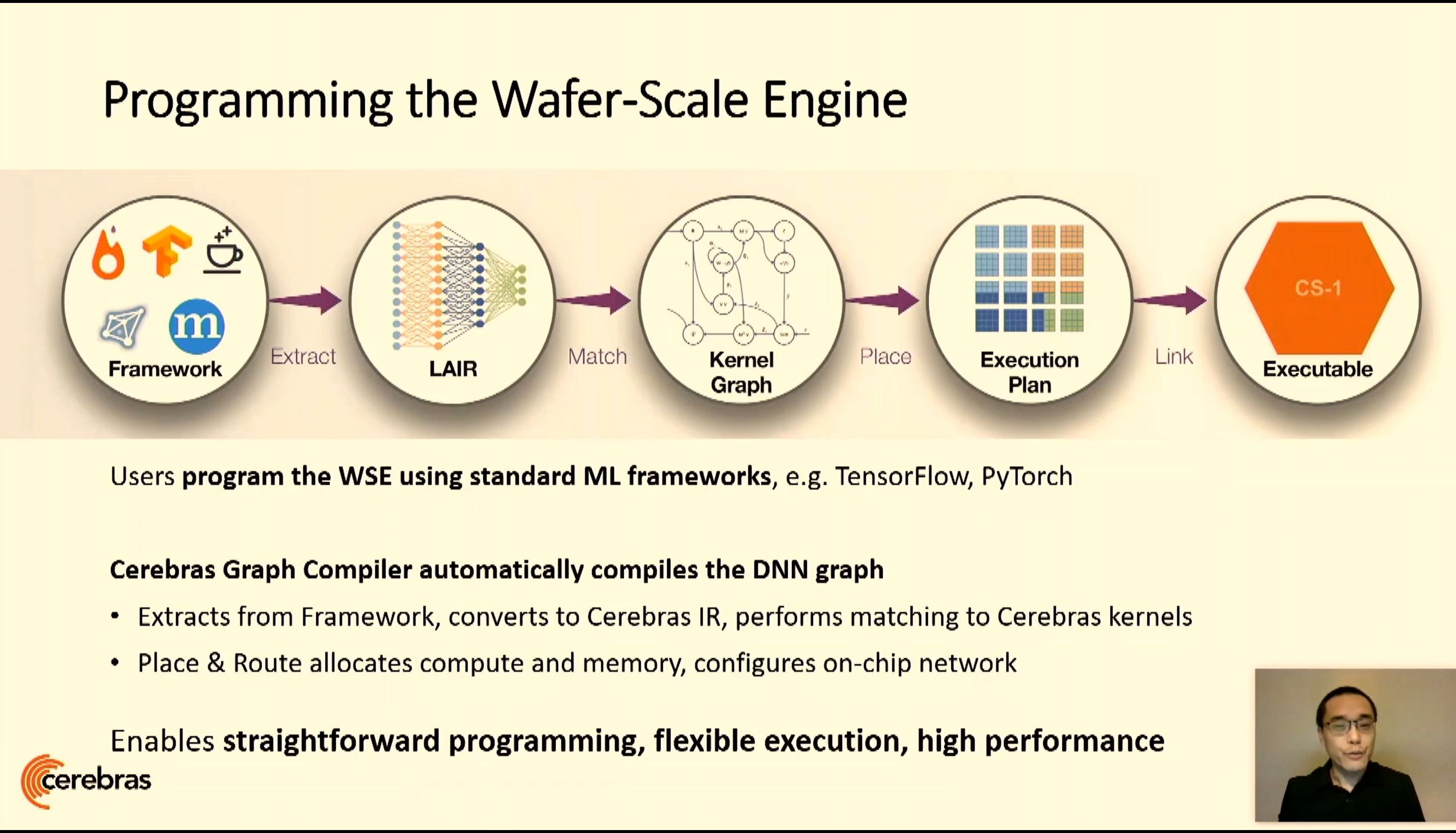
06:07PM EDT - Cerebras graph compiler
06:07PM EDT - extract compute graph, create a graph in the WSE format, route kernals on the fabric, then create executable
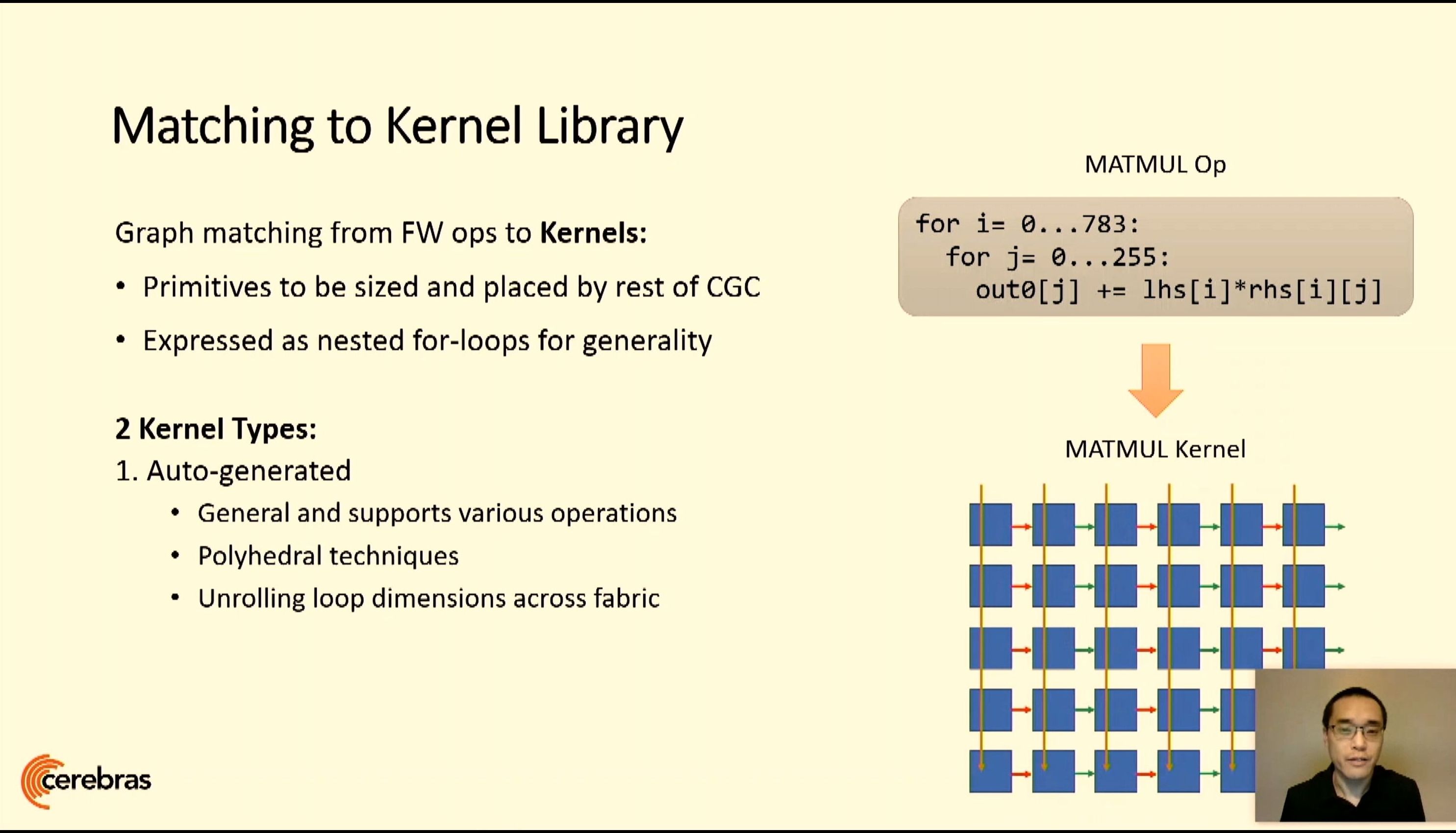
06:09PM EDT - Graph matching for matrix multiply loops
06:09PM EDT - Supports hand optimized kernels
06:10PM EDT - Model-parallel and data-parallel optimization with the compiler
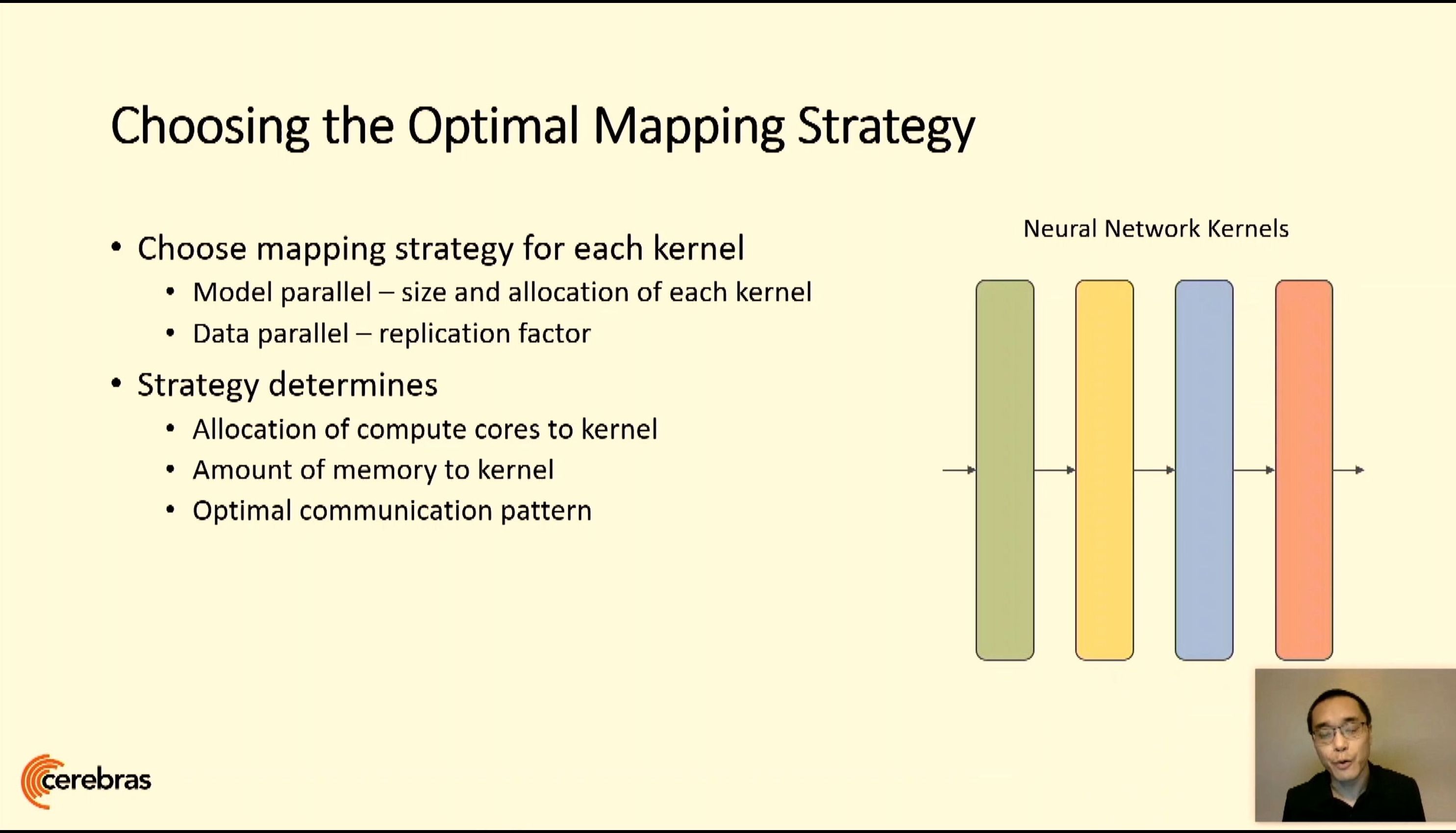

06:11PM EDT - Trade-off as resources vs compute for each kernel
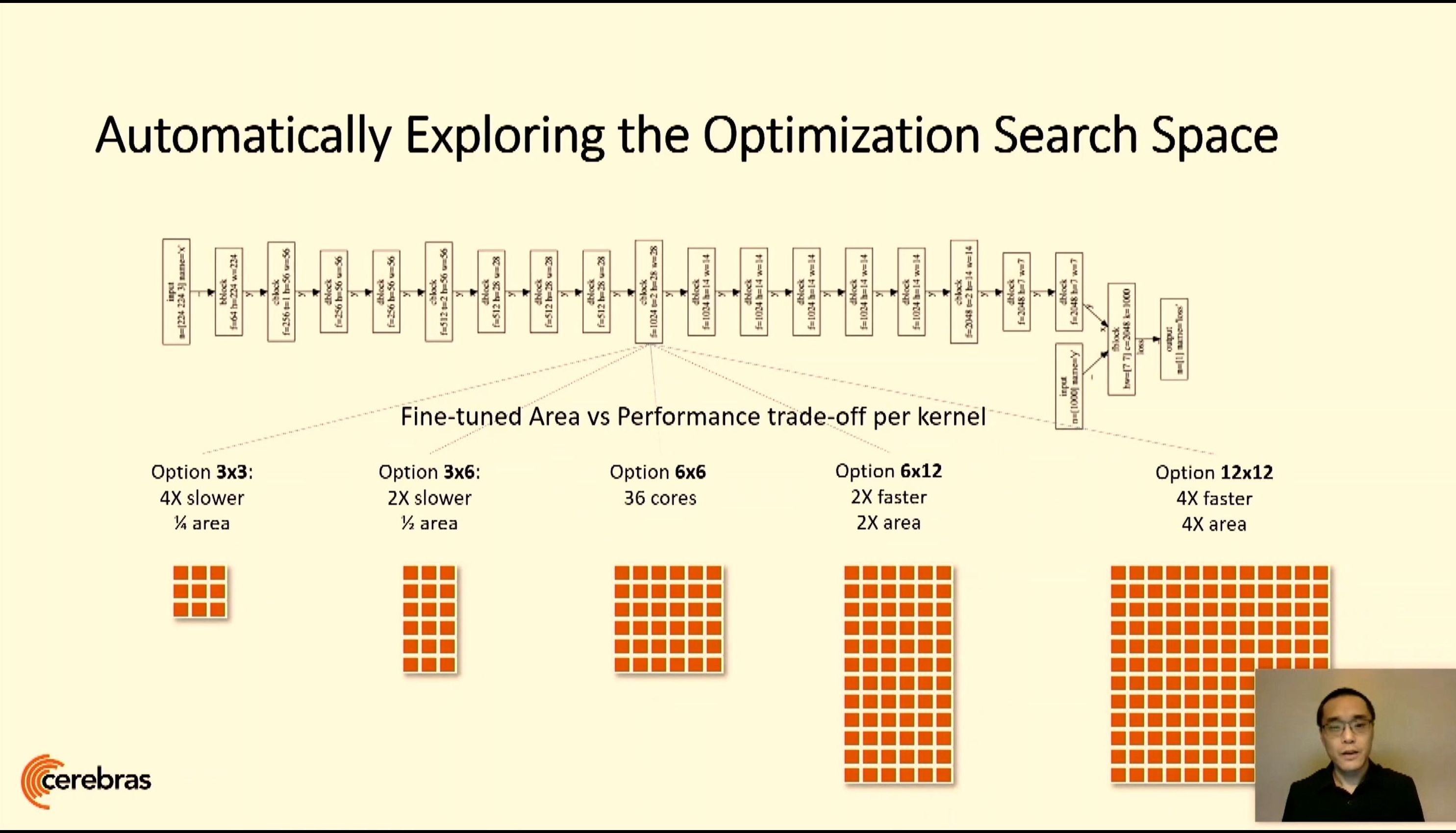
06:12PM EDT - All kernels can be resized as needed
06:12PM EDT - All functionally identical

06:13PM EDT - Global optimization function to maximize throughput and utilization
06:14PM EDT - 3 key benefits


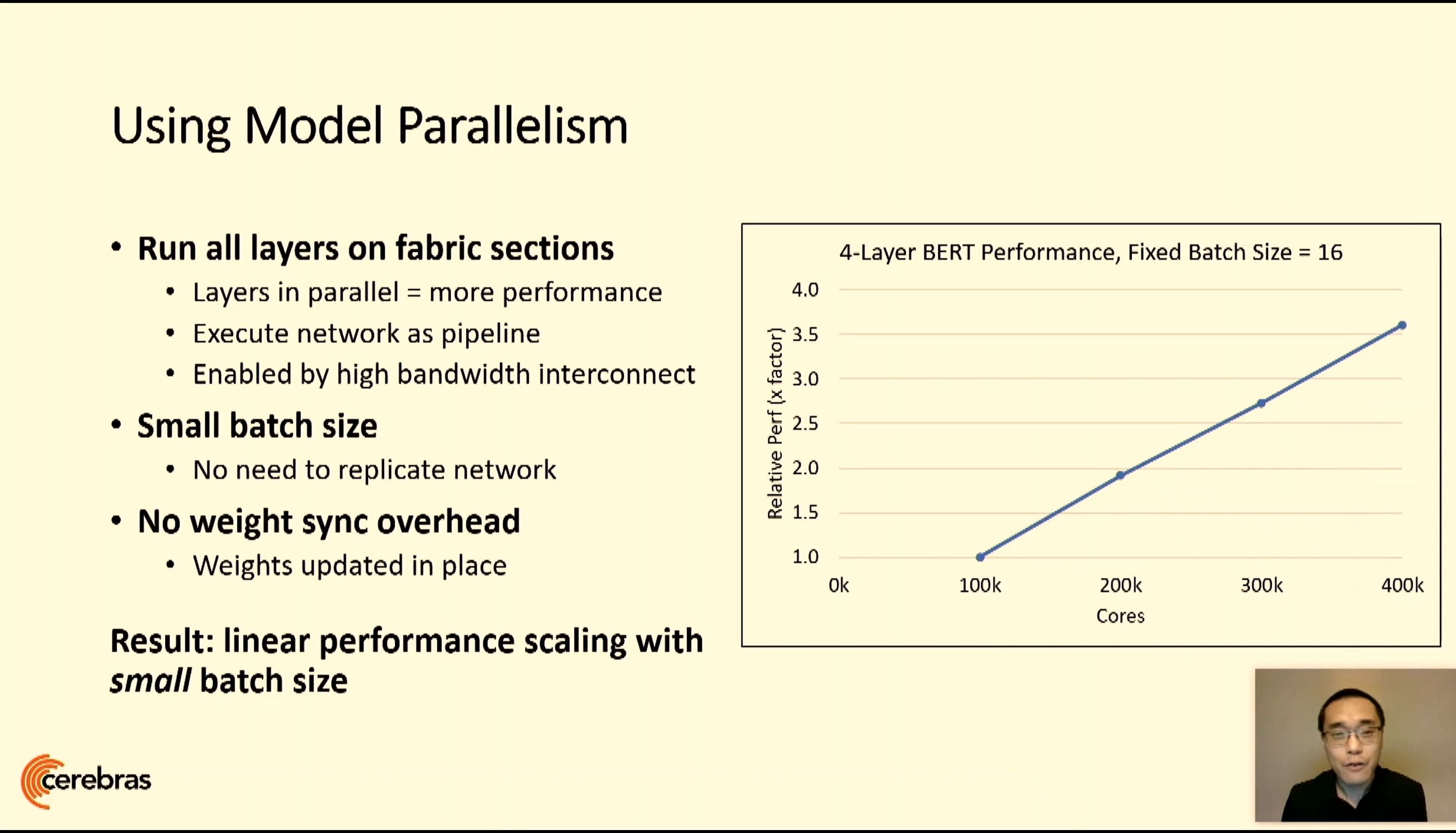
06:15PM EDT - Flexible parallelism
06:16PM EDT - Enough Fabric performance to connect everything at scale
06:16PM EDT - Otherwise slow across GPUs or a cluster
06:16PM EDT - Small batch size has super high utilization
06:16PM EDT - no weight sync overhead


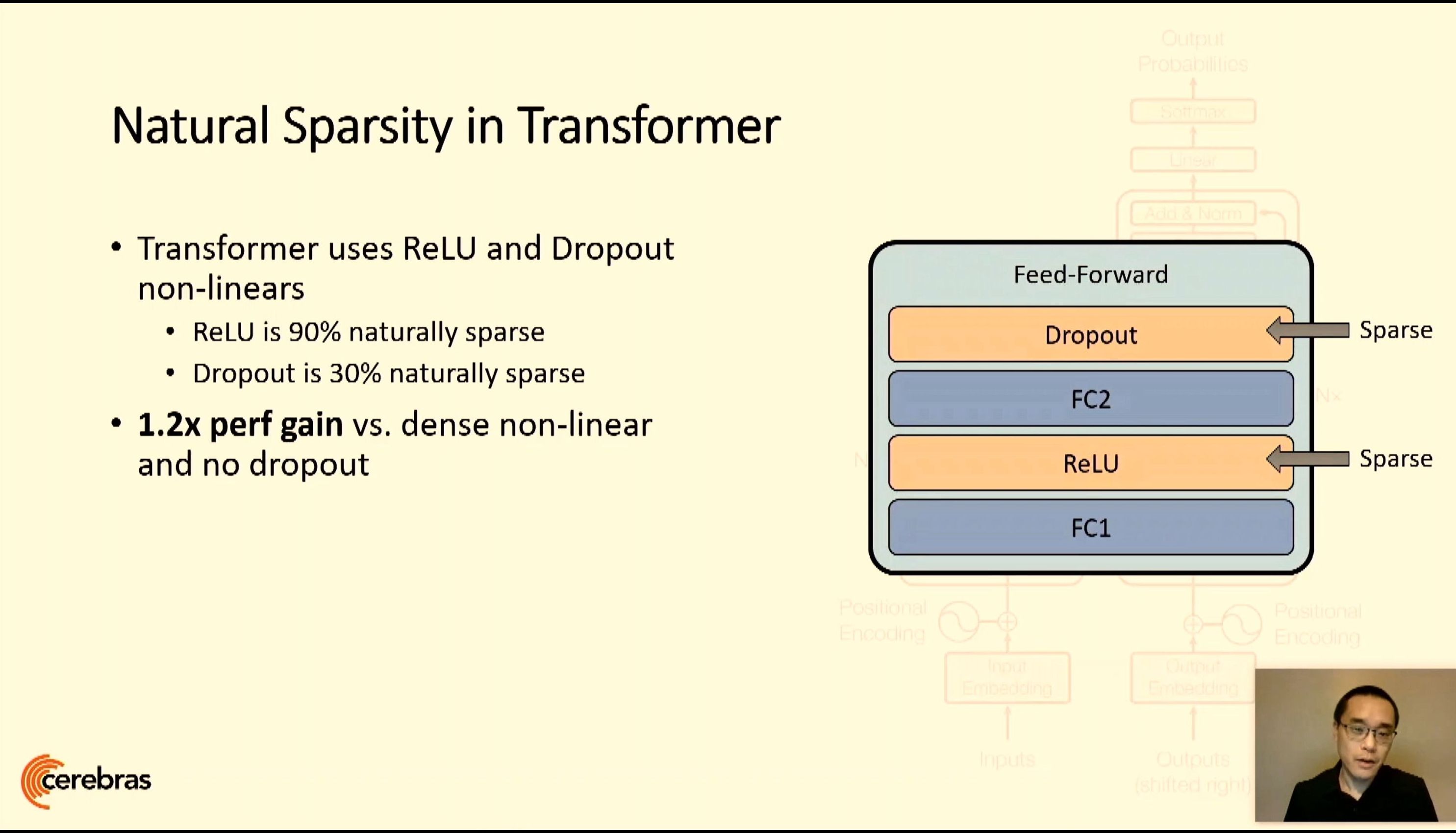
06:19PM EDT - Core is designed for sparsity
06:20PM EDT - Intrinsic sparsity harvesting
06:20PM EDT - filters out all zeros


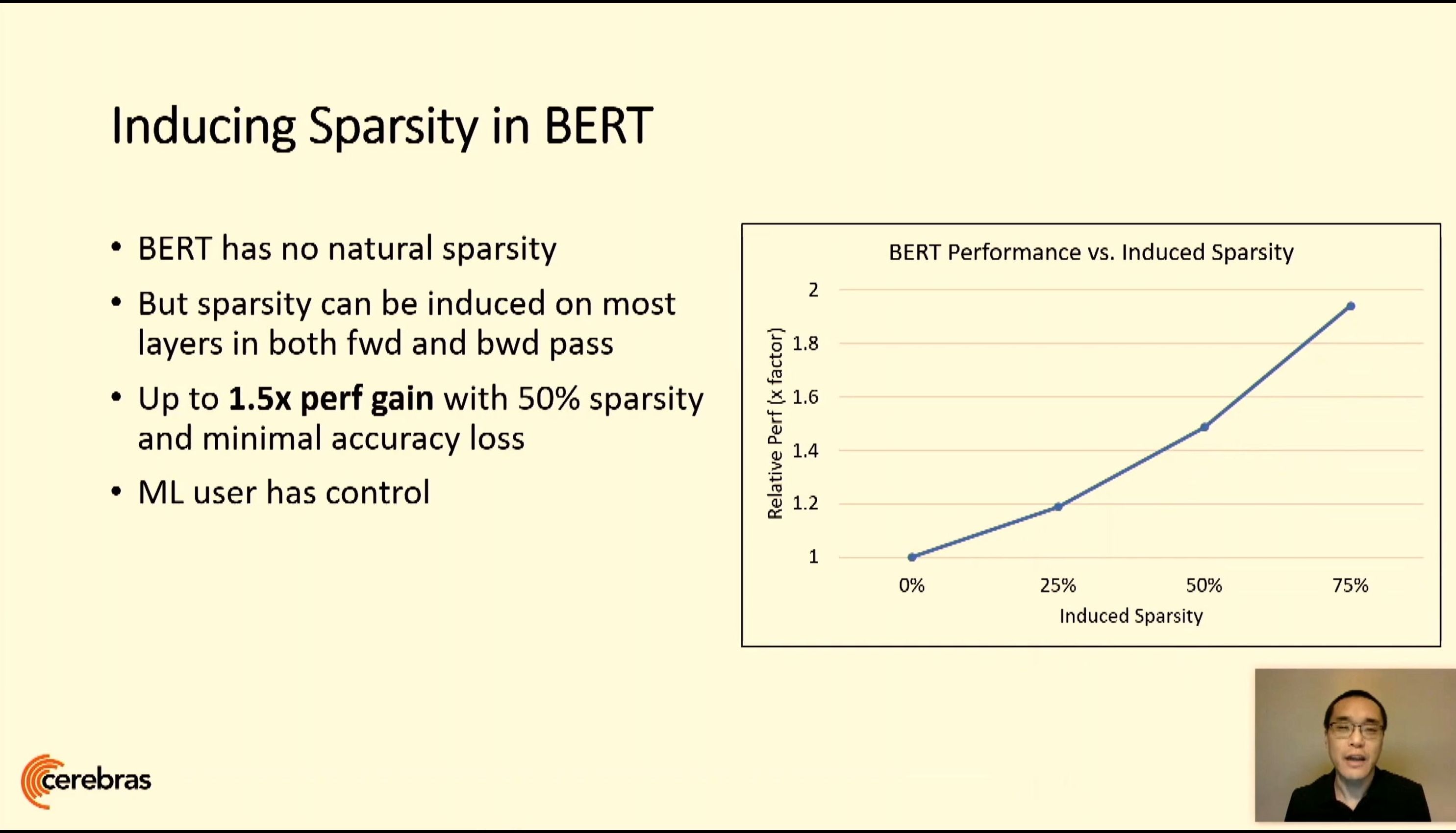
06:23PM EDT - ML user has full control over full range of sparse techniques

06:23PM EDT - WSE is MIMD, each core can be independent
06:24PM EDT - True variable sequence length support
06:24PM EDT - No padding required
06:24PM EDT - Higher utilization for irregular models
06:25PM EDT - Dynamic depth networks

06:26PM EDT - only need to process exact lengths of sequences


06:26PM EDT - World's most powerful AI computer
06:27PM EDT - Complete flexibility due to the size of the wafer scale engine

06:28PM EDT - Working in the lab today
06:29PM EDT - More info later this year
06:29PM EDT - Q&A team
06:29PM EDT - time*
06:31PM EDT - Q: What's the main benefit of WSE? A: Bypassing the issues with workloads that need multiple GPU/TPU/DPU. Opens up novel techniques that wouldn't run on traditional hardware at any sense of speed
06:32PM EDT - Q: How to feed the beast? A: Traditional server might be the GPU/TPU, so the next one is IO. We are a system company, our product is the full system, as we control all aspects of the system. We have a 1.2 Tb/s ethernet interconnect to feed the engine to keep up with the compute
06:34PM EDT - Q: How long does it take a compile a model over 400k units? A: It's an algorithmically complex search space problem. Annealing and heuristics bring that down - we are borrowing many ideas from the EDA industry. Our problem is simpler than billions of LEs on FPGAs, so we're in the minutes.
06:34PM EDT - That's a wrap. Next talk is 4096 RISC-V chip








0 Comments
View All Comments