Hot Chips 2020 Live Blog: Intel's Xe GPU Architecture (5:30pm PT)
by Dr. Ian Cutress on August 17, 2020 8:30 PM EST- Posted in
- GPUs
- Intel
- Live Blog
- Xe
- Hot Chips 32

08:37PM EDT - Intel's Xe talk, by David Blythe
08:37PM EDT - David did the Intel Architecture Xe talk


08:38PM EDT - Going forward in architecture than previously covered by integrated GPU
08:38PM EDT - Moving from Gen to Xe -> exascale for everyone
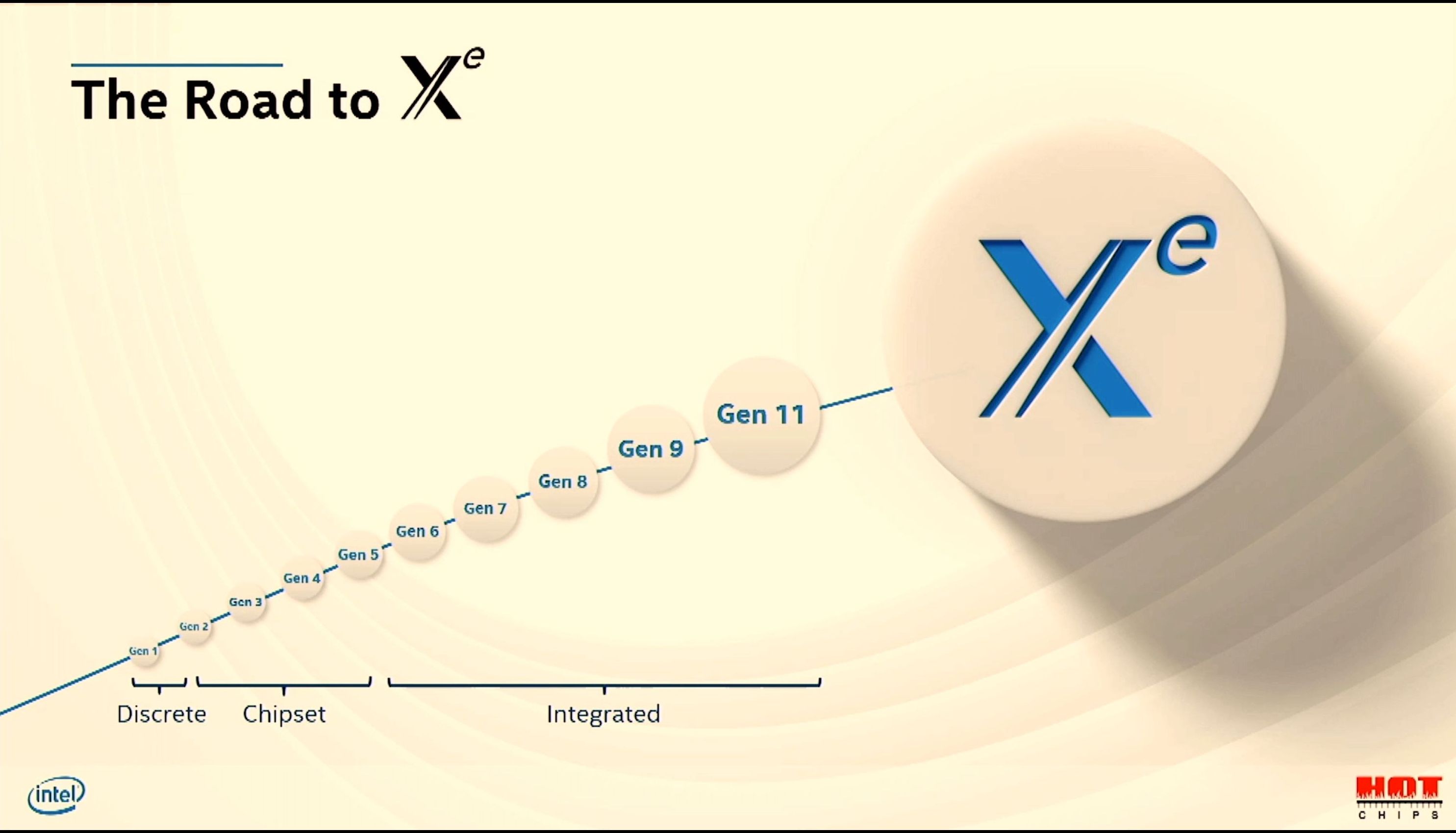

08:38PM EDT - Goals: increase SIMD lanes from 10s to 1000s
08:38PM EDT - Add new capabilities - matrix tensors, ray tracing, virtualization, etc
08:38PM EDT - Also PPA improvements
08:39PM EDT - Required a lot of new design over Gen11
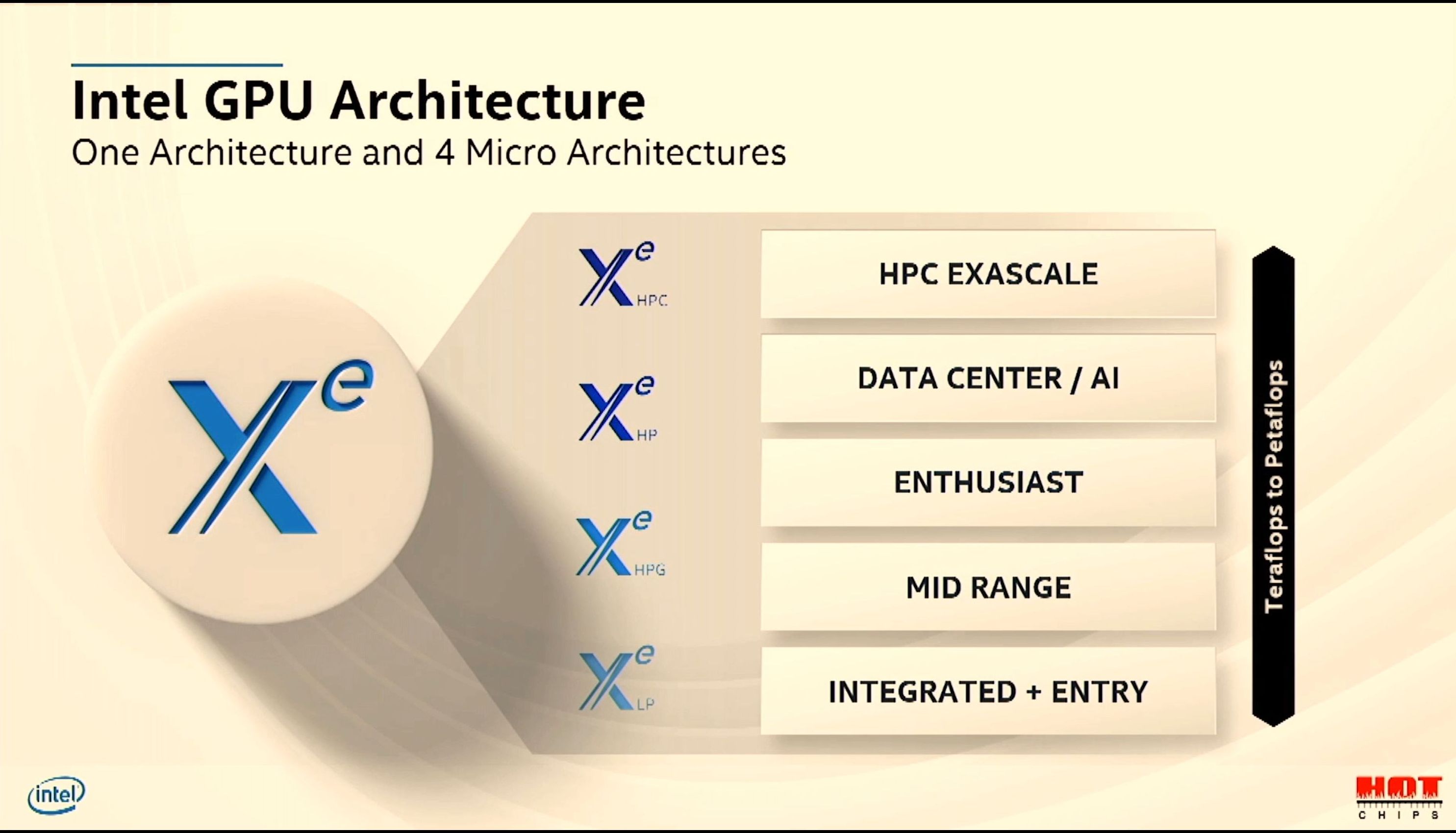
08:39PM EDT - Xe will scale from LP to HPG, HP, HPC
08:39PM EDT - Optimized for different market requirements
08:40PM EDT - Going beyond just adding execution units - but optimizing each segment with individual requirements
08:40PM EDT - Such as ray tracing, media, FP64 etc
08:40PM EDT - LP is integrated and entry
08:40PM EDT - HPG is Mid-range and Enthusiast
08:40PM EDT - HP is Datacenter and AI
08:40PM EDT - HPC is exascale
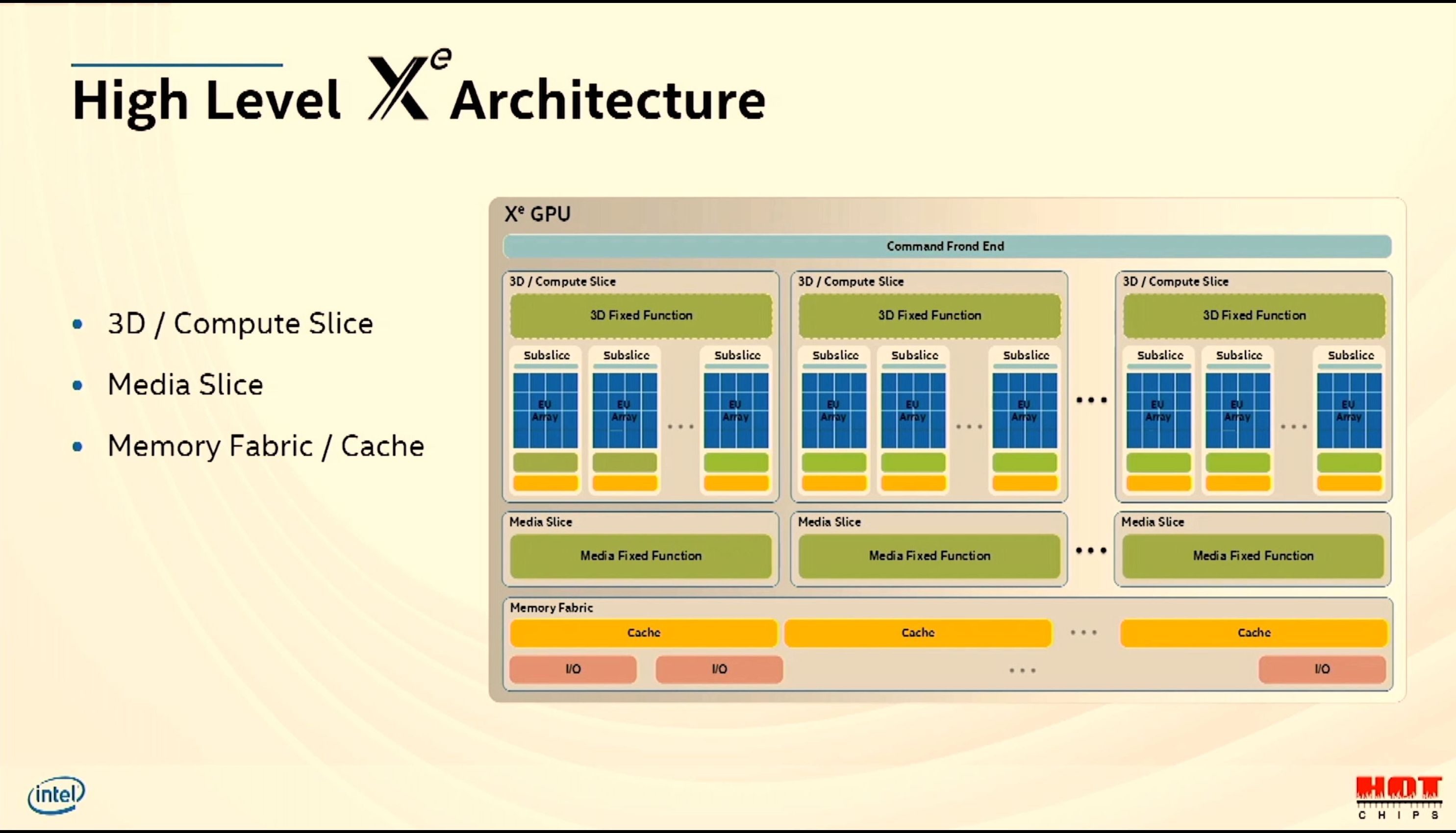
08:41PM EDT - There is a high-level Xe architecture
08:41PM EDT - 3D/Compute slice, media slice, memory fabric
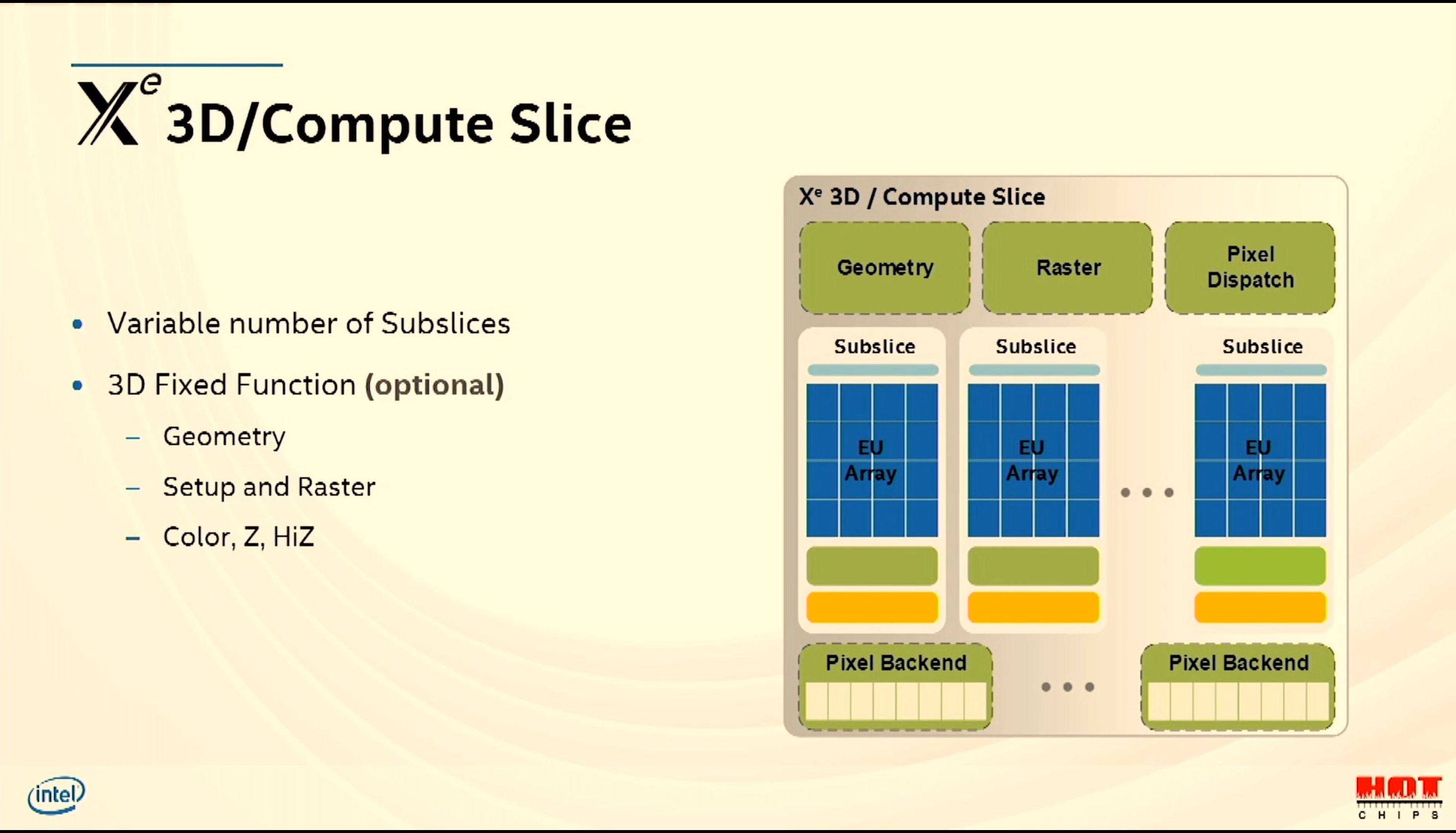
08:41PM EDT - Each slice has sub-slices
08:41PM EDT - programmable shaders
08:41PM EDT - (Each compute slice is 96 EUs)
08:42PM EDT - Geometry has moved inside the slice and now distributed
08:42PM EDT - Slice size is adjustable

08:42PM EDT - Sub-slice has 16 EUs
08:42PM EDT - Fixed function units (optional based on segment)
08:42PM EDT - 16 EUs = 128 SIMD lanes
08:43PM EDT - hardware blocks for ray tracing
08:43PM EDT - XeHPG that uses Ray Tracing in the lab today
08:43PM EDT - L1 scratch pad

08:43PM EDT - Xe Execution Unit
08:44PM EDT - 8 INT/FP ports, 2 complex math

08:44PM EDT - Media processing can be scaled as well with media slices
08:44PM EDT - de-noise, de-interlace, tone mapping is all here
08:45PM EDT - can distribute a stream across mutiple slices

08:45PM EDT - Xe Memory Fabric
08:45PM EDT - L3 and Rambo cache
08:45PM EDT - Lots of optional stuff here
08:46PM EDT - Allows scaling to 1000 of EUs
08:46PM EDT - Requires multiple dies

08:46PM EDT - Low level tile disaggregation
08:47PM EDT - Mutliple tiles work as separate GPUs or a single GPU
08:47PM EDT - EMIB does XeMF

08:47PM EDT - Xe Link enables XeMF from GPU-to-GPU

08:48PM EDT - XeHP with HBM2e
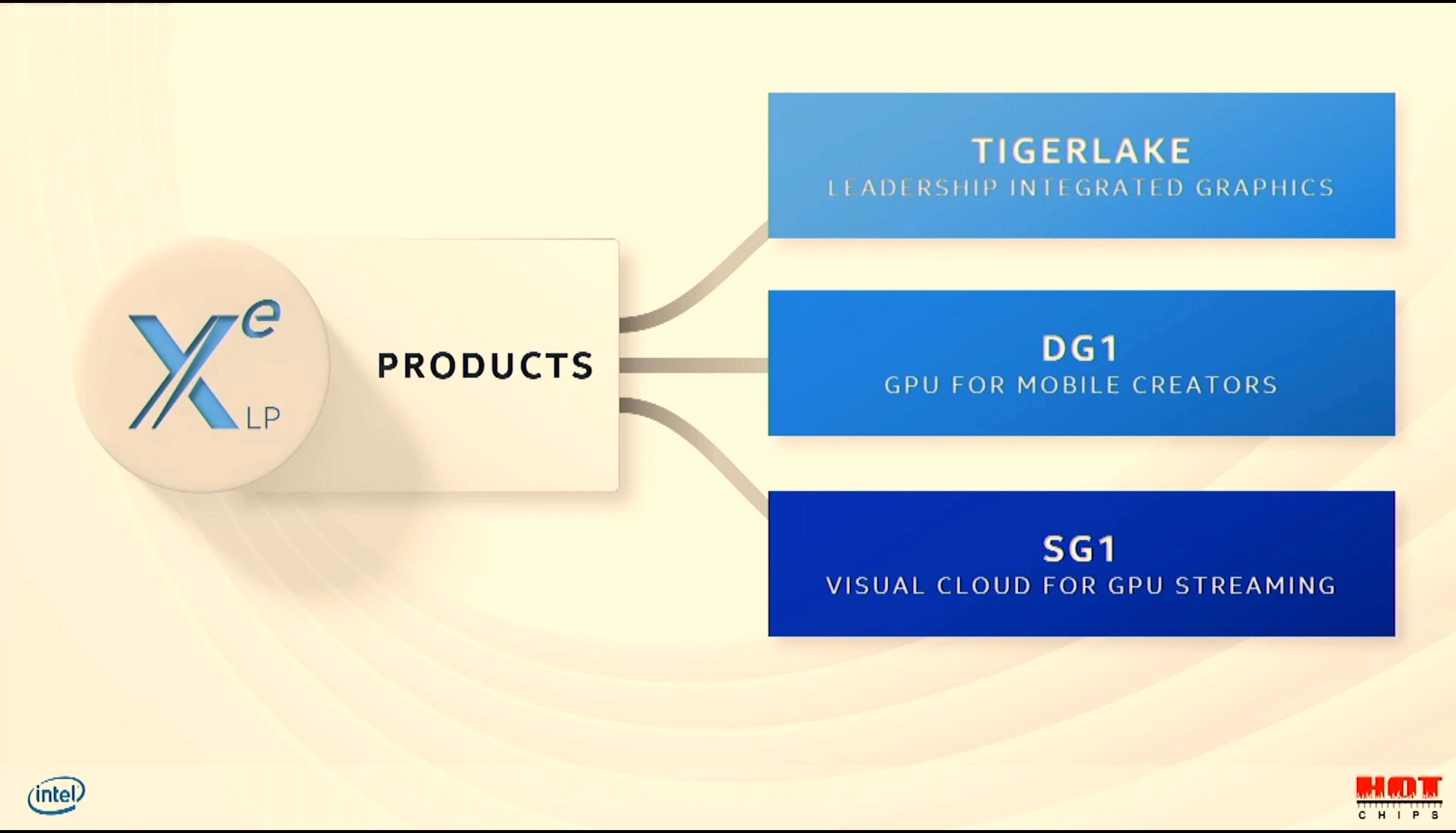
08:48PM EDT - XeLP is low power optimized
08:48PM EDT - Tiger Lake, SG1, and DG1 will all be XeLP
08:49PM EDT - Tiger Lake goal was to increase perf 2x in graphics


08:49PM EDT - 1.5x larger GPU EUs with scaled assets
08:49PM EDT - 96 EUs, 1536 32-bit ops/clock
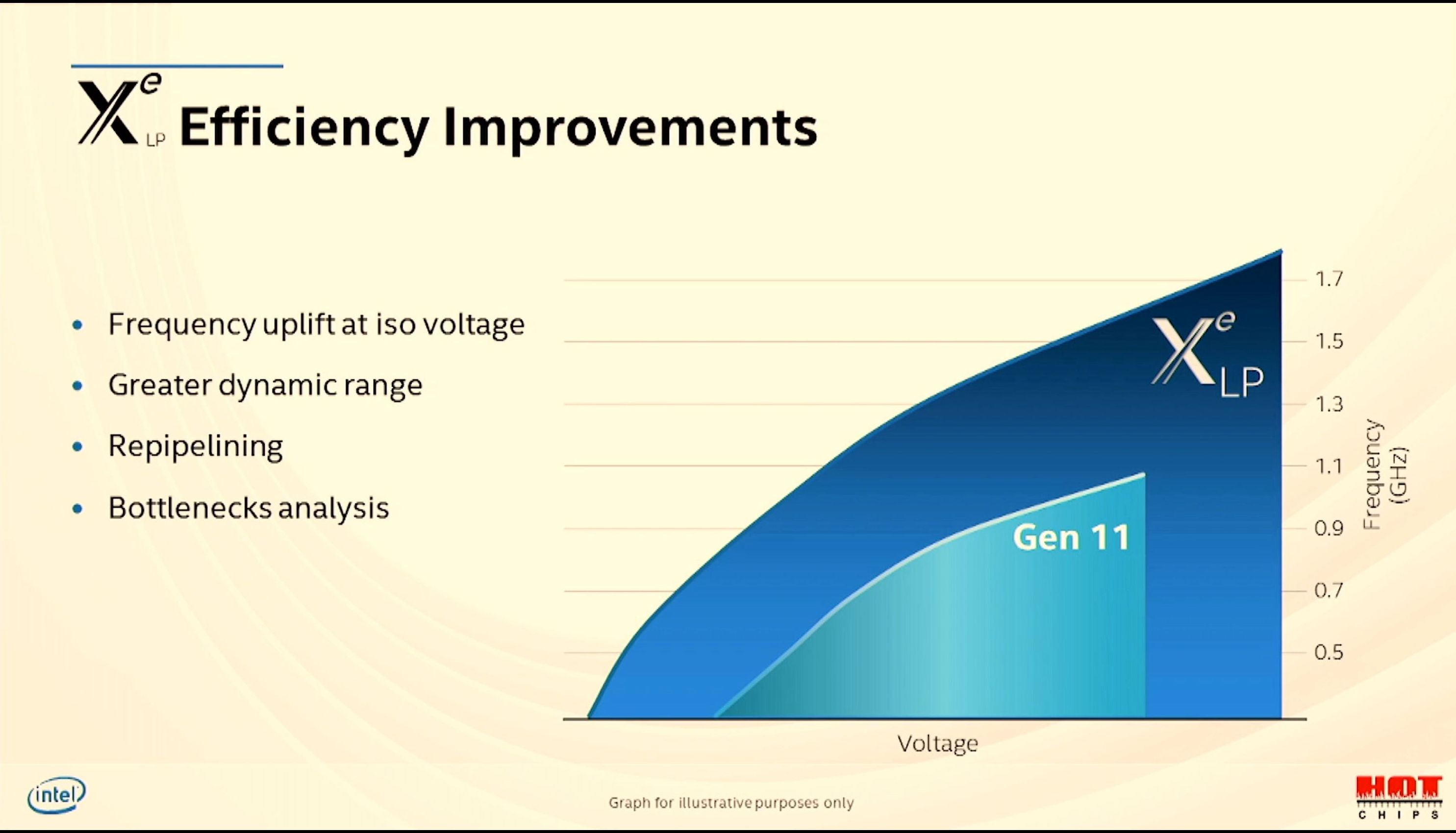
08:50PM EDT - Frequency is also 1.5x
08:51PM EDT - Tiger Lake Xe has greater dynamic range
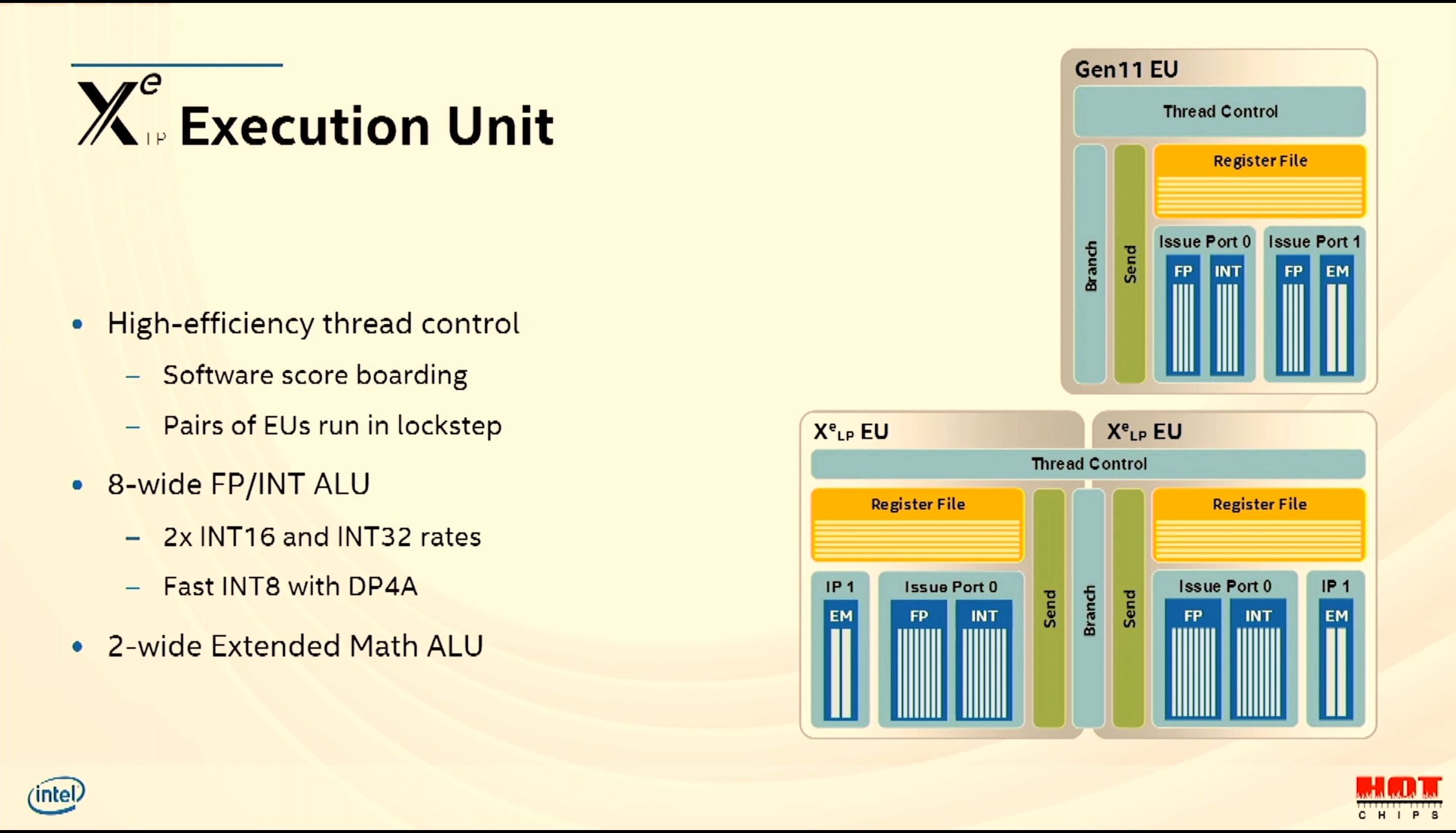
08:51PM EDT - software score boarding per EU
08:52PM EDT - Pairs of EUs run in lockstep due to shared thread control
08:52PM EDT - 2xINT16 and INT32 rates, fast INT8 dot-product that accumulates into one INT32 result
08:52PM EDT - Each subslice has one L1, and up to 16 MB L3


08:54PM EDT - AV1 support
08:54PM EDT - XeHP parts in the lab

08:55PM EDT - XeHP up to 4 tiles
08:55PM EDT - 1 tile can to 10.6 GFLOP FP32
08:56PM EDT - 2 tile can to 21161 GFLOP FP32
08:56PM EDT - 4-tile can do ~42k GFLOP FP32
08:56PM EDT - Shows XeHP can scale

08:57PM EDT - Xe will spread across different nodes and manufacturing

08:58PM EDT - Q&A time
08:58PM EDT - Q: Xe Matrix via AMX? A: There will be an API, disclosed later
08:58PM EDT - Q: Open source driver code? A: Yes, for integrated and discrete
08:59PM EDT - Q: Why 1 RT unit per 16 EUs A: That seemed like the proper scalability. RT throughput can be modulated too - it isn't just a fixed size thing. No details at this time.
09:00PM EDT - Q: Tile-to-tile vs Xe Link ? A: Tile-to-tile is internal protocol in XeMF, but XeLink exposes the protocol, no details but lightweight
09:00PM EDT - Q: CXL? A: There's an intent to support, still working out the details
09:01PM EDT - Q: CPU to GPU comms? A: For XeHPC there is an intent to support CXL
09:02PM EDT - Q: Why are 3D fixed functions optional? A: Not all areas need 3D, like XeHPC. Can turn them off at design time if needed. GPUs can't always carry baggage in specified products
09:03PM EDT - Q: Threads in an EU? A: Not changed much. 1 or 2, in TGL supports 7, little higher in the others
09:04PM EDT - Q: API for ray tracing? A: The standard ones. Khronos, MS. For the high-end rendering, there will be OneAPI for more production type rendering. More details later, similar to embree on CPU
09:04PM EDT - That's a wrap. Next up is Xbox








28 Comments
View All Comments
ikjadoon - Monday, August 17, 2020 - link
I hope someone asks about LPDDR5 in the Q&A. How critical is that to Xe-LP Performance? Have Intel's internal benchmarks been on LP5 or LP4X?If you look at Comet Lake, very slow LPDDR4X uptake. Why does Intel think partners will re-refresh their laptops for LPDDR5, when most refused to do so for Comet Lake? Or are we going to see a delay in Tiger Lake launches until LPDDR5 variants are released?
IntelUser2000 - Monday, August 17, 2020 - link
Isn't it obvious? Cometlake uses the HD 620 graphics, which works fine with LPDDR3. LPDDR4X just raises cost and complexity.Tigerlake with 4x+ performance can take advantage of it.
ikjadoon - Monday, August 17, 2020 - link
>LPDDR4X just raises cost and complexity.I didn't tell Intel to backport LPDDR4X. That was Intel's own foolish choice.
KimGitz - Monday, August 17, 2020 - link
I'm hoping LPDDR5 will show up in Q1 2021 along with the 6-8 cores 45-65W Tiger Lake H....ikjadoon - Tuesday, August 18, 2020 - link
Fair enough. I can't find many announcements, but Samsung is supposed to begin their 3rd-gen 1z node for LPDDR5-6400, meanwhile Tiger Lake only supports LPDDR5-5500. Perhaps laptops will get the 2nd-gen 1y node's LPDDR4-5500?Anandtech article a few months ago: https://www.anandtech.com/show/15547/samsung-start...
trivik12 - Monday, August 17, 2020 - link
Date for TGL-U/Y is in 2 weeks. Dont think that will change. I think LPDDR5 will be niche and will probably used only in high end ultrabooks like Surface book or XPS or Spectre or Thinkpad. Otherwise we will see laptops with LPDDR4x or low end with DDR4.ikjadoon - Tuesday, August 18, 2020 - link
That's true, but I do recall some Ice Lake laptops not being announced until CES 2020, i.e., four months later.But I agree w/ your assessment: perhaps the higher-end models will just delay TGL models until LPDDR5 capacity is high enough.
Spunjji - Tuesday, August 18, 2020 - link
Most Ice Lake laptops came later, IIRC. The original launch was with a limited number of devices.I'd be more prepared to wager that the majority of devices won't have it at all, and once again we'll be left in that situation where you don't know how a given device will perform until you see a review.
KimGitz - Monday, August 17, 2020 - link
Xe HPG is on an external process, apparently on TSMC's 6nm process. Since Intel delayed their 7nm process I was expecting them to use TSMC's 7nm. I feel like Intel have been working on the Xe-HPG in secret and were planning on releasing it on their own 7nm in 2021 but when that got delayed they went with TSMC's 7nm but with everyone turning to TSMC's 7nm, TSMC could only offer decent capacity at 6nm. This is why Intel disclosed the Xe-HPG now because they have secured a deal with TSMC. The Xe GPU Architecture and the Micro-Architectures IP are not tied to a particular process node and can be ported to any internal or external process.JayNor - Tuesday, August 18, 2020 - link
HPG also back in the lab already, so arrangement with the external fab must have been some time ago.